Jak počítač reprezentuje text?
Jak počítač ukládá text? Od Morseovy abecedy přes ASCII až po Unicode a UTF-8. Článek ukazuje, jak se písmena proměnila v jedničky a nuly, proč vznikaly problémy s kódováním a jak UTF-8 sjednotilo způsob, jakým počítače rozumí textu napříč světem.
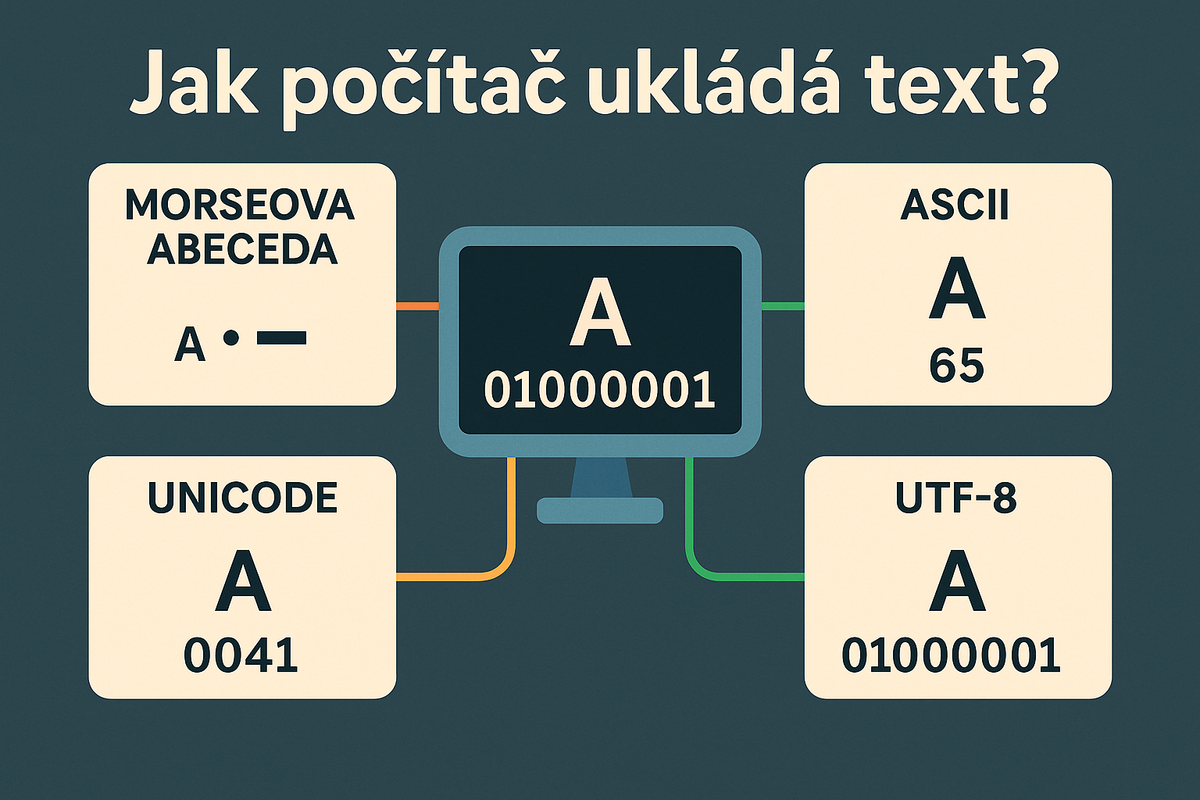
V minulém článku jsem se naučili jak počítač reprezentuje čísla. A nyní se podíváme, jak reprezentuje písmena a celý text.

Nyní už víme, že všechna data v počítači jsou tvořena pouze z jedniček a nul. Naučili jsme se, že tyto bity mohou reprezentovat čísla. Abychom to pochopili, museli jsme udělat určitou mentální gymnastiku – přijmout, že kombinace nul a jedniček mohou vyjadřovat libovolné číslo. Teď však chceme, aby počítač uměl pracovat i s písmeny a textem, což je pro nás další stupeň abstrakce.
To odpovídá i historickému vývoji počítačů. První elektronické počítače, například ENIAC (1945), byly ve své podstatě obrovské kalkulačky – dokázaly provádět pouze číselné výpočty. Programování tehdy znamenalo fyzicky přepojovat kabely nebo nastavovat přepínače, a výsledky se vypisovaly na děrné štítky nebo zobrazovaly pomocí světelných indikátorů.
Později se počítače začaly používat pro zpracování velkého množství dat – například pro evidenci zaměstnanců či účetní záznamy. Aby to bylo možné, museli vývojáři vymyslet způsob, jak budou počítače rozumět písmenům a dalším znakům.
Už v 50. letech 20. století měly děrné štítky sadu znaků, která zahrnovala písmena A–Z, číslice 0–9 a několik speciálních symbolů.
Jak to ale fungovalo?
Na to si ještě chvíli počkáme. Než tomu porozumíme, musíme se vrátit o více než sto let zpět – do doby, kdy počítače ještě neexistovaly. A jak už možná tušíte, všechno začalo elektřinou.
Konkrétně v roce 1831, kdy Michael Faraday objevil elektromagnetickou indukci. Tento objev znamenal okamžik, kdy lidé dokázali vytvářet elektrický proud a pomocí vodičů ho ovládat – a tím otevřeli cestu ke všem pozdějším elektronickým vynálezům, včetně počítačů.
Objev elektromagnetické indukce odstartoval éru, ve které se lidé naučili využívat elektrický proud k přenosu informací. Prvním praktickým krokem byl telegraf. Ten dokázal pomocí elektrických impulsů posílat zprávy na dálku – a to už ve 40. letech 19. století.
V roce 1837 představili Samuel Morse a Alfred Vail systém, který dokázal převést písmena a čísla na kombinace krátkých a dlouhých signálů – tečky a čárky, známé jako Morseova abeceda.
To byl přelomový okamžik: poprvé v historii byla písmena reprezentována elektrickými signály.
Morseova tabulka - písmena
| Písmeno | Kód | Písmeno | Kód |
|---|---|---|---|
| A | ·− | N | −· |
| B | −··· | O | −−− |
| C | −·−· | P | ·−−· |
| D | −·· | Q | −−·− |
| E | · | R | ·−· |
| F | ··−· | S | ··· |
| G | −−· | T | − |
| H | ···· | U | ··− |
| I | ·· | V | ···− |
| J | ·−−− | W | ·−− |
| K | −·− | X | −··− |
| L | ·−·· | Y | −·−− |
| M | −− | Z | −−·· |
Morseova tabulka - číslice
| Číslo | Kód |
|---|---|
| 1 | ·−−−− |
| 2 | ··−−− |
| 3 | ···−− |
| 4 | ····− |
| 5 | ····· |
| 6 | −···· |
| 7 | −−··· |
| 8 | −−−·· |
| 9 | −−−−· |
| 0 | −−−−− |
Morseova tabulka - interpunkce
| Znak | Kód | Popis |
|---|---|---|
| . | ·−·−·− | tečka |
| , | −−··−− | čárka |
| ? | ··−−·· | otazník |
| ' | ·−−−−· | apostrof |
| ! | −·−·−− | vykřičník |
| / | −··−· | lomítko |
| ( | −·−−· | levá závorka |
| ) | −·−−·− | pravá závorka |
| & | ·−··· | spojka „a“ |
| : | −−−··· | dvojtečka |
| ; | −·−·−· | středník |
| = | −···− | rovnítko |
| + | ·−·−· | plus |
| − | −····− | mínus |
| _ | ··−−·− | podtržítko |
| " | ·−··−· | uvozovky |
| @ | ·−−·−· | zavináč |
A právě tímto způsobem se zrodila myšlenka, že text lze uložit a zpracovat jako čísla – princip, na kterém stojí veškeré moderní programování.
Ještě na chvíli se zastavme u Morseovy abecedy a udělejme další myšlenkový krok.
Co kdybychom tečky a čárky nahradili nulami a jedničkami?
Tečka by představovala nulu a čárka jedničku.
Dostali bychom tak následující tabulku:
| Písmeno | Morse | Binárně |
|---|---|---|
| A | ·− | 01 |
| B | −··· | 1000 |
| C | −·−· | 1010 |
| D | −·· | 100 |
| E | · | 0 |
| F | ··−· | 0010 |
| G | −−· | 110 |
| H | ···· | 0000 |
| I | ·· | 00 |
| J | ·−−− | 0111 |
| K | −·− | 101 |
| L | ·−·· | 0100 |
| M | −− | 11 |
| N | −· | 10 |
| O | −−− | 111 |
| P | ·−−· | 0110 |
| Q | −−·− | 1101 |
| R | ·−· | 010 |
| S | ··· | 000 |
| T | − | 1 |
| U | ··− | 001 |
| V | ···− | 0001 |
| W | ·−− | 011 |
| X | −··− | 1001 |
| Y | −·−− | 1011 |
| Z | −−·· | 1100 |
Příklad textu
Slovo SOS v Morseovce:
··· --- ···
V binární podobě:
000|111|000
Pokud přidáme oddělovač slov /:
000|111|000 / 000|111|000
Nyní již vidíme, že pomocí jedniček a nul dokážeme reprezentovat jednotlivá písmena. Později, když se objevili počítače, vývojáři na tuto myšlenku navázali.
ASCII a kódování
Morseovu abecedu bychom teoreticky mohli použít i pro ukládání textu, ale má dvě zásadní nevýhody.
První spočívá v tom, že každé písmeno má jinou délku zápisu.
Když se podíváme na její binární podobu, zjistíme, že pro písmena E a T stačí 1 bit, pro A, I, M a N potřebujeme 2 bity, a postupně se dostáváme až k písmenům, která vyžadují 4 bity. Pokud do systému zahrneme i čísla a speciální znaky, délka zápisu může dosáhnout až šesti bitů.
Druhou nevýhodou je, že Morseova abeceda nemá jednoznačně definovaný znak pro oddělení písmen a slov, což by při ukládání textu v počítači způsobovalo problémy s čitelností a zpracováním dat.
Proto bylo nutné vytvořit jednotný systém pro převod znaků na binární kód.
Tím se stala tabulka ASCII (American Standard Code for Information Interchange) – první široce přijatý standard pro kódování textu, který vznikl v roce 1963.
Před ASCII měl totiž každý výrobce počítačů vlastní kódovou tabulku, takže data mezi různými stroji nebyla kompatibilní.
V době vzniku ASCII byly běžné 8bitové počítače, jejichž procesor dokázal pracovat s 8 bity najednou, tedy s 2⁸ = 256 různými hodnotami.
Původní ASCII tabulka však používala pouze 7 bitů (128 znaků) – osmý bit sloužil jako paritní bit pro kontrolu správnosti přenosu dat.
Paritní bit
Paritní bit je doplňkový bit, který se přidává k datům (např. k bajtu) pro jednoduchou kontrolu chyb při přenosu.
Jeho úkolem je zajistit, aby celkový počet jedniček byl buď sudý (sudá parita), nebo lichý (lichá parita).
Pokud se při přenosu jeden bit změní, příjemce to podle parity pozná.
Paritní bit ale neumí určit, kde se chyba stala, ani ji opravit.
Původní tabulka vypadala takto:
| Dec | Binární | Znak | Popis |
|---|---|---|---|
| 0 | 0000000 | NUL | Null |
| 1 | 0000001 | SOH | Start of Heading |
| 2 | 0000010 | STX | Start of Text |
| 3 | 0000011 | ETX | End of Text |
| 4 | 0000100 | EOT | End of Transmission |
| 5 | 0000101 | ENQ | Enquiry |
| 6 | 0000110 | ACK | Acknowledge |
| 7 | 0000111 | BEL | Bell (pípnutí) |
| 8 | 0001000 | BS | Backspace |
| 9 | 0001001 | TAB | Horizontal Tab |
| 10 | 0001010 | LF | Line Feed (nový řádek) |
| 11 | 0001011 | VT | Vertical Tab |
| 12 | 0001100 | FF | Form Feed (nová stránka) |
| 13 | 0001101 | CR | Carriage Return |
| 14 | 0001110 | SO | Shift Out |
| 15 | 0001111 | SI | Shift In |
| 16 | 0010000 | DLE | Data Link Escape |
| 17 | 0010001 | DC1 | Device Control 1 |
| 18 | 0010010 | DC2 | Device Control 2 |
| 19 | 0010011 | DC3 | Device Control 3 |
| 20 | 0010100 | DC4 | Device Control 4 |
| 21 | 0010101 | NAK | Negative Acknowledge |
| 22 | 0010110 | SYN | Synchronous Idle |
| 23 | 0010111 | ETB | End of Transmission Block |
| 24 | 0011000 | CAN | Cancel |
| 25 | 0011001 | EM | End of Medium |
| 26 | 0011010 | SUB | Substitute |
| 27 | 0011011 | ESC | Escape |
| 28 | 0011100 | FS | File Separator |
| 29 | 0011101 | GS | Group Separator |
| 30 | 0011110 | RS | Record Separator |
| 31 | 0011111 | US | Unit Separator |
| 32 | 0100000 | (mezera) | Space |
| 33 | 0100001 | ! | vykřičník |
| 34 | 0100010 | " | uvozovky |
| 35 | 0100011 | # | hash |
| 36 | 0100100 | $ | dolar |
| 37 | 0100101 | % | procento |
| 38 | 0100110 | & | ampersand |
| 39 | 0100111 | ' | apostrof |
| 40 | 0101000 | ( | levá závorka |
| 41 | 0101001 | ) | pravá závorka |
| 42 | 0101010 | * | hvězdička |
| 43 | 0101011 | + | plus |
| 44 | 0101100 | , | čárka |
| 45 | 0101101 | - | mínus |
| 46 | 0101110 | . | tečka |
| 47 | 0101111 | / | lomítko |
| 48 | 0110000 | 0 | číslice nula |
| 49 | 0110001 | 1 | číslice jedna |
| 50 | 0110010 | 2 | číslice dvě |
| 51 | 0110011 | 3 | číslice tři |
| 52 | 0110100 | 4 | číslice čtyři |
| 53 | 0110101 | 5 | číslice pět |
| 54 | 0110110 | 6 | číslice šest |
| 55 | 0110111 | 7 | číslice sedm |
| 56 | 0111000 | 8 | číslice osm |
| 57 | 0111001 | 9 | číslice devět |
| 58 | 0111010 | : | dvojtečka |
| 59 | 0111011 | ; | středník |
| 60 | 0111100 | < | menší než |
| 61 | 0111101 | = | rovnítko |
| 62 | 0111110 | > | větší než |
| 63 | 0111111 | ? | otazník |
| 64 | 1000000 | @ | zavináč |
| 65 | 1000001 | A | velké A |
| 66 | 1000010 | B | velké B |
| 67 | 1000011 | C | velké C |
| 68 | 1000100 | D | velké D |
| 69 | 1000101 | E | velké E |
| 70 | 1000110 | F | velké F |
| 71 | 1000111 | G | velké G |
| 72 | 1001000 | H | velké H |
| 73 | 1001001 | I | velké I |
| 74 | 1001010 | J | velké J |
| 75 | 1001011 | K | velké K |
| 76 | 1001100 | L | velké L |
| 77 | 1001101 | M | velké M |
| 78 | 1001110 | N | velké N |
| 79 | 1001111 | O | velké O |
| 80 | 1010000 | P | velké P |
| 81 | 1010001 | Q | velké Q |
| 82 | 1010010 | R | velké R |
| 83 | 1010011 | S | velké S |
| 84 | 1010100 | T | velké T |
| 85 | 1010101 | U | velké U |
| 86 | 1010110 | V | velké V |
| 87 | 1010111 | W | velké W |
| 88 | 1011000 | X | velké X |
| 89 | 1011001 | Y | velké Y |
| 90 | 1011010 | Z | velké Z |
| 91 | 1011011 | [ | hranatá závorka vlevo |
| 92 | 1011100 | \ | zpětné lomítko |
| 93 | 1011101 | ] | hranatá závorka vpravo |
| 94 | 1011110 | ^ | stříška |
| 95 | 1011111 | _ | podtržítko |
| 96 | 1100000 | ` | obrácený apostrof |
| 97 | 1100001 | a | malé a |
| 98 | 1100010 | b | malé b |
| 99 | 1100011 | c | malé c |
| 100 | 1100100 | d | malé d |
| 101 | 1100101 | e | malé e |
| 102 | 1100110 | f | malé f |
| 103 | 1100111 | g | malé g |
| 104 | 1101000 | h | malé h |
| 105 | 1101001 | i | malé i |
| 106 | 1101010 | j | malé j |
| 107 | 1101011 | k | malé k |
| 108 | 1101100 | l | malé l |
| 109 | 1101101 | m | malé m |
| 110 | 1101110 | n | malé n |
| 111 | 1101111 | o | malé o |
| 112 | 1110000 | p | malé p |
| 113 | 1110001 | q | malé q |
| 114 | 1110010 | r | malé r |
| 115 | 1110011 | s | malé s |
| 116 | 1110100 | t | malé t |
| 117 | 1110101 | u | malé u |
| 118 | 1110110 | v | malé v |
| 119 | 1110111 | w | malé w |
| 120 | 1111000 | x | malé x |
| 121 | 1111001 | y | malé y |
| 122 | 1111010 | z | malé z |
| 123 | 1111011 | { | složená závorka vlevo |
| 124 | 1111100 | | | svislá čára |
| 125 | 1111101 | } | složená závorka vpravo |
| 126 | 1111110 | ~ | vlnovka |
| 127 | 1111111 | DEL | Delete |
Originální tabulku najdete přímo na webových stránkách tohoto standardu: https://www.ascii-code.com/ASCII.
Prvních 32 znaků (0–31) tvoří tzv. řídicí znaky.
Tyto znaky nesloužily k zápisu textu, ale k ovládání zařízení, jako byly telegrafy, tiskárny nebo terminály.
Reprezentovaly různé akce – například:
- LF (Line Feed) – přechod na nový řádek,
- CR (Carriage Return) – návrat na začátek řádku,
- TAB (Tabulátor) – odsazení,
- BEL (Bell) – zvukové upozornění, tzv. „pípnutí“.
Většina těchto znaků se dnes již běžně nepoužívá, ale některé přežily v moderní podobě – například \n a \r v textových souborech nebo ESC používaný pro barevné sekvence v terminálu.
Na dalších pozicích ASCII tabulky se nacházejí znaky běžně používané v textu.
Protože ji vytvářeli američtí inženýři, obsahuje pouze anglickou abecedu, číslice a základní interpunkční znaky.
ASCII byla ve své době přelomová, ale jak už jsme naznačili, měla i zásadní omezení.
Největším problémem bylo, že neobsahovala znaky jiných jazyků – chyběla například diakritika, řecká písmena, azbuka nebo asijské znaky.
Dalším limitem bylo, že kvůli tzv. paritnímu bitu měla tabulka k dispozici pouze 7 bitů, tedy 128 znaků, což je polovina z možností, které by poskytoval 8bitový systém (256 znaků).
Výrobci počítačů proto začali rozšiřovat původní ASCII tabulku, každý po svém.
A tím se situace vrátila zpět do doby před rokem 1963 – znovu vznikalo mnoho nekompatibilních standardů, a textové soubory nebylo možné spolehlivě přenášet mezi různými zařízeními.
Rozšíření ASCII
Aby bylo možné zapisovat znaky dalších jazyků, začaly se v 70. a 80. letech objevovat tzv. rozšířené ASCII sady. Ty využívaly všech 8 bitů (tedy 256 kombinací) a přidávaly k původním 128 znakům další – například písmena s diakritikou, matematické symboly nebo grafické prvky pro textové rozhraní.
Problém však byl, že každý výrobce nebo region si vytvořil vlastní rozšířenou sadu.
Například:
- ISO 8859-1 (Latin-1) – používala se v západní Evropě a obsahovala znaky pro francouzštinu, němčinu, španělštinu a další jazyky.
- ISO 8859-2 (Latin-2) – byla určena pro střední a východní Evropu, tedy i pro češtinu, polštinu nebo maďarštinu.
- Windows-1250 – proprietární kódování od Microsoftu, které se používalo v systému Windows pro stejné jazyky jako Latin-2, ale mělo odlišné rozložení.
Tato rozšíření sice umožnila používat národní znaky, ale zároveň znovu přinesla problém nekompatibility.
Text napsaný v jednom systému se při otevření na jiném často zobrazoval chybně – místo písmen s diakritikou se objevovaly podivné symboly nebo otazníky.
Ukažme si to na příkladu. Věta: "Nechť již hříšné saxofony ďáblů rozezvučí síň úděsnými tóny waltzu, tanga a quickstepu." je označována jako pangram a měla by obsahovat všechna písmena české abecedy. Pokud tuto větu zakódujeme v sadě ISO 8859-2 (Latin-2), dostaneme tento binární kód.
01001110 01100101 01100011 01101000 10111011 00100000 01101010 01101001 10111110 00100000 01101000 11111000 11101101 10111001 01101110 11101001 00100000 01110011 01100001 01111000 01101111 01100110 01101111 01101110 01111001 00100000 11101111 11100001 01100010 01101100 11111001 00100000 01110010 01101111 01111010 01100101 01111010 01110110 01110101 11101000 11101101 00100000 01110011 11101101 11110010 00100000 11111010 01100100 11101100 01110011 01101110 11111101 01101101 01101001 00100000 01110100 11110011 01101110 01111001 00100000 01110111 01100001 01101100 01110100 01111010 01110101 00101100 00100000 01110100 01100001 01101110 01100111 01100001 00100000 01100001 00100000 01110001 01110101 01101001 01100011 01101011 01110011 01110100 01100101 01110000 01110101 00101110A nyní budeme chtít tento text přečíst na Windows, který pro východní Evropu používá kódování Windows-1250, které má jinou konverzní tabulku. Výsledný text bude vypadat takto:
Nech» jiľ hříąné saxofony ďáblů rozezvučí síň úděsnými tóny waltzu, tanga a quickstepu.To vám možná přijde povědomé, zvlášť pokud koukáte na stažené filmy a používáte české titulky ve formátu s koncovkou *.srt. Autoři titulků používají dodneška různé kódování znaků a přehrávače mají nastavený jeden určitý základní standard.
Vše si sami může vyzkoušet sami s tímto online nástrojem, kde můžete zkusit různé znakové sady.

Unicode
Máme konec 80. let a celé 90. roky a na scéně se znovu objevuje dobře známý problém:
Texty vytvořené v jednom programu nebo na jednom zařízení nebylo možné správně přečíst jinde.
Zní to povědomě? Ano — už v roce 1963 vzniklo ASCII, aby tento problém vyřešilo.
A o téměř třicet let později jsme byli zase na začátku.
Jak se říká — inovace se někdy točí v kruhu.
V roce 1988 vznikla skupina Unicode Working Group, jejímž cílem bylo sjednotit všechny existující znakové sady do jednoho systému.
O tři roky později, v roce 1991 – tedy v roce, kdy jsem se narodil, kdy vznikl Linux a také Python – se tato skupina proměnila v Unicode Consortium, neziskovou organizaci, která spravuje a rozvíjí celý standard dodnes.
Cílem Unicode bylo přidělit každému znaku na světě jedno unikátní číslo.
První verze, Unicode 1.0 z roku 1991, používala pro každý znak 16 bitů – tedy 2¹⁶ = 65 536 možných znaků.
Tato kapacita stačila na pokrytí většiny moderních jazyků, včetně latinky, cyrilice, řečtiny, arabštiny i hlavních asijských písem.
Postupem času se ukázalo, že 65 536 znaků je stále málo a Unicode se postupně rozšiřoval. Navíc Unicode jen přiřazuje znaku číslo a neříká nic o jeho binární reprezentaci.
UTF-8
Na Unicode později navázala skupina standardů nazývaná UTF – Unicode Transformation Formats.
Ty určují, jak se jednotlivé znaky převádějí na binární kód, tedy jak se fyzicky ukládají do paměti nebo přenášejí po síti.
První variantou byl UTF-32.
V tomto formátu má každý znak pevnou délku 32 bitů (4 bajty), takže každý znak je reprezentován jedním čtyřbajtovým číslem.
Tento přístup byl jednoduchý, ale velmi neefektivní z hlediska paměti, protože i běžný anglický text, který by stačil uložit v jednom bajtu na znak, zabíral čtyřnásobek prostoru.
V roce 1993 vyvinuli v Bellových laboratořích inženýři Ken Thompson a Rob Pike úspornější formát UTF-8.
Jejich myšlenka byla elegantní:
- Pokud znak spadá do původního ASCII rozsahu (0–127), uloží se jako jeden bajt (8 bitů).
- Pokud je mimo ASCII, uloží se jako sekvence 2 až 4 bajtů, podle toho, jak velké číslo znak reprezentuje.
Díky tomu je UTF-8 zpětně kompatibilní s ASCII a zároveň dokáže zapsat všechny znaky Unicode, což z něj postupně udělalo nejpoužívanější formát kódování textu na světě.
Možná se ptáte jak program pozná, že je znak 1 nebo více bajtů? Mohl by to číst jako sekvenci více znaků. Princip je následující. První bajt začíná určitým počtem jedniček, které říkají, kolik bajtů celý znak zabírá.
| Počet bajtů | Vzor prvního bajtu | Význam |
|---|---|---|
| 1 bajt | 0xxxxxxx |
ASCII znak (0–127) |
| 2 bajty | 110xxxxx |
Začátek dvoubajtového znaku |
| 3 bajty | 1110xxxx |
Začátek tříbajtového znaku |
| 4 bajty | 11110xxx |
Začátek čtyřbajtového znaku |
| Následující bajty | 10xxxxxx |
Pokračování předchozího znaku |
Zde jsou příklady jednotlivých znaků:
| Znak | Unicode | Počet bajtů | Binární zápis | Hexadecimální zápis |
|---|---|---|---|---|
| A | U+0041 | 1 | 01000001 |
41 |
| č | U+010D | 2 | 11000100 10001101 |
C4 8D |
| € | U+20AC | 3 | 11100010 10000010 10101100 |
E2 82 AC |
| 😀 | U+1F600 | 4 | 11110000 10011111 10011000 10000000 |
F0 9F 98 80 |
Teď si ukážeme jak by se napsalo slovo "Český", které obsahuje vícebajtové písmena (Č a ý):
| Znak | Unicode | Počet bajtů | Binární | Hexadecimálně |
|---|---|---|---|---|
| Č | U+010C | 2 | 11000100 10001100 |
C4 8C |
| e | U+0065 | 1 | 01100101 |
65 |
| s | U+0073 | 1 | 01110011 |
73 |
| k | U+006B | 1 | 01101011 |
6B |
| ý | U+00FD | 2 | 11000011 10111101 |
C3 BD |
Celou tabulku Unicode znaků naleznete na oficiální webové stránce organizace Unicode zde: https://www.unicode.org/charts/. Nicméně oficiální stránka není zcela přehledná, proto doporučuji tuto neoficiální variantu: https://symbl.cc/en/unicode-table/. Momentální verze Unicode obsahuje okolo 160 tis. znaků.
Kde jsme dnes?
Na první pohled by se mohlo zdát, že problém s nečitelnými znaky a „rozsypaným textem“ už dávno patří minulosti. Unicode a jeho nejrozšířenější forma UTF-8 sjednotily způsob, jak se znaky ukládají do paměti i přenášejí mezi systémy. Přesto se s chybami v kódování můžeme setkat dodnes.
- Staré soubory a software – některé titulky, CSV nebo e-maily jsou stále uložené ve starších kódováních, jako Windows-1250 nebo ISO-8859-2. Novější programy je pak čtou jako UTF-8 a zobrazí nesmysly.
- Chybějící nebo špatně uvedené kódování – pokud soubor neříká, v jakém kódování je, musí to program jen odhadnout. To často končí zkomoleným textem.
- Různé platformy – Windows dlouho používal své lokální kódování, zatímco Linux a macOS přešly na UTF-8. Při kopírování souborů mezi systémy tak může dojít ke ztrátě českých znaků.
- Různé zápisy téhož znaku – Unicode dovoluje zapsat stejný znak několika způsoby. Například písmeno
ěmůže být jeden znak nebo kombinacee+ˇ. Pro člověka jsou stejné, ale pro počítač ne. - Nové znaky a emoji – standard Unicode se stále rozšiřuje. Některé aplikace nebo fonty nové znaky ještě neumí zobrazit.
I když je tedy UTF-8 vývojově nejdokonalejší a dnes univerzálně používané, úplné zmizení problémů s kódováním brzdí právě historické dědictví a nejednotnost softwaru.
Nejlepším řešením je vše nové ukládat v UTF-8 a staré soubory převádět pomocí textového editoru nebo nástroje iconv.